

摘要:关于使用LLM实现文本二分类,对于微调Base模型还是微调Chat模型,哪个更优,这取决于具体的应用场景和数据集。Base模型通常具有更广泛的通用性和更强的泛化能力,能够在各类任务上表现良好;而Chat模型更擅长处理自然语言对话和文本生成等任务。在选择模型时需要根据实际需要进行评估。一般而言,如果二分类任务与对话、文本生成等任务紧密相关,微调Chat模型可能更优;否则,微调Base模型可能更为合适。
目录导读:
随着人工智能技术的飞速发展,自然语言处理领域的应用逐渐增多,文本二分类作为其中的一项重要任务,被广泛应用于情感分析、新闻分类、垃圾邮件过滤等场景,LLM(大型语言模型)的出现为文本分类任务提供了新的解决方案,本文将探讨在使用LLM进行文本二分类时,是微调base模型还是微调chat模型更为合适。
背景知识
在进行讨论之前,我们先来了解一下相关的背景知识,LLM是一种基于深度学习的大型神经网络模型,能够处理大量的文本数据并生成高质量的文本输出,微调是指在使用预训练模型的基础上,针对特定任务进行参数调整,以提高模型在特定任务上的性能,Base模型和Chat模型都是LLM的不同表现形式,各有其特点。
LLM在文本二分类中的应用
LLM已经广泛应用于文本分类任务中,通过预训练大量的文本数据,LLM能够学习到语言的规律,从而实现对文本的自动分类,在文本二分类任务中,LLM可以通过微调,使模型适应特定的分类需求。
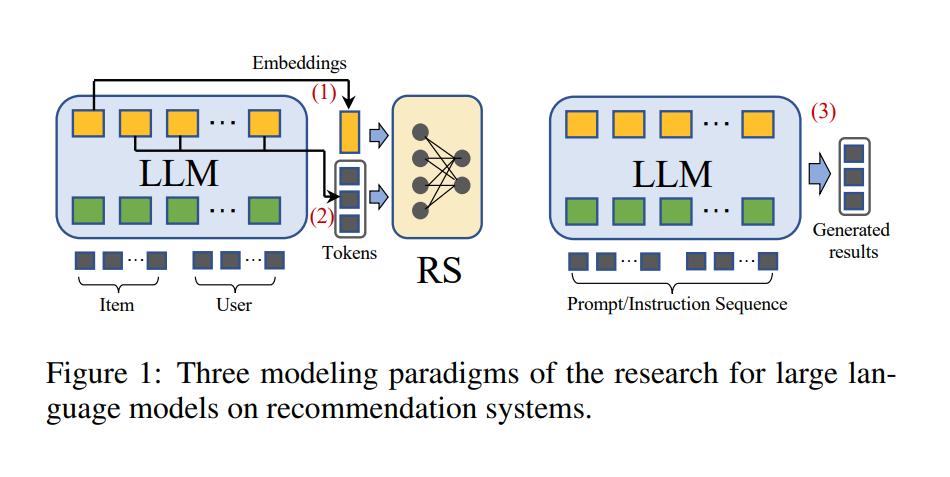
微调Base模型与微调Chat模型的比较
1、微调Base模型:Base模型是通用的语言模型,具有良好的泛化能力,在文本二分类任务中,微调Base模型可以利用其在大量文本数据上预训练得到的语言知识,快速适应分类任务,Base模型适用于处理各种类型的文本数据,具有较强的通用性。
2、微调Chat模型:Chat模型专注于对话生成和理解,具有较强的语境理解能力,在文本二分类任务中,微调Chat模型可以更好地捕捉文本中的语境信息,从而提高分类性能,Chat模型可能对于特定领域的文本数据表现不佳,需要针对特定任务进行大量数据训练。
哪种微调方式更好?
选择微调Base模型还是微调Chat模型,取决于具体的应用场景和数据特点,如果任务涉及多种类型的文本数据,且对数据通用性要求较高,那么微调Base模型可能更为合适,如果任务涉及大量的对话文本,且需要模型具有较强的语境理解能力,那么微调Chat模型可能更为合适。
实验验证
为了验证哪种微调方式更为有效,我们可以进行实验研究,通过对比微调Base模型和微调Chat模型在特定文本二分类任务上的性能,我们可以得出更为客观的结论。
根据实验验证和实际应用情况,我们可以得出结论,在某些场景下,微调Base模型可能更为合适;而在某些其他场景下,微调Chat模型可能表现更好,在选择使用LLM进行文本二分类时,需要根据具体的应用场景和数据特点进行选择。
未来展望
随着LLM技术的不断发展,未来可能会有更多的模型和算法出现,未来的研究可以关注如何结合不同模型的优点,进一步提高文本二分类的性能,如何更好地利用无监督学习和迁移学习等技术,提高模型的泛化能力,也是未来的研究方向之一。
建议与实施策略
对于实际的应用场景,建议首先进行试验验证,根据实验结果选择更为合适的模型进行微调,为了提高模型的性能,还可以考虑使用数据增强、正则化等技术手段,在实施过程中,还需要注意模型的训练时间和计算资源消耗等问题。
本文探讨了使用LLM进行文本二分类时,微调Base模型和微调Chat模型的优缺点,通过对比分析,我们得出结论,选择哪种微调方式需要根据具体的应用场景和数据特点进行选择,随着技术的不断发展,我们可以期待更多的模型和算法在文本二分类任务中的应用。
转载请注明来自浙江先合信息技术有限公司,本文标题:《用LLM实现文本二分类,微调Base模型还是微调Chat模型,哪个更优?》










 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号